Contents
はじめに
公式ヘルプ記事はこちら笑
間違ってもループを回して値を足し合わせたり、値を比較したりしないよう、標準で用意されている集計関数については全て頭に入れておきたいところです。
簡易まとめ
- AVG(field):平均
- COUNT():レコード数
- COUNT(field):当該の項目がnullではないレコードの数
- COUNT_DISTINCT(field):当該の項目のnullを除いたユニークな値の総数
- MIN(field):最小値
- MAX(field):最大値
- SUM(field):合計値
COUNT()とCOUNT(field)の違い
Count()がレコード数を返すのに対して、Count(field)はその項目に値の入っているレコードの数を返します。
| Name | State |
| ねこ株式会社 | 東京都 |
| いぬ株式会社 | 東京都 |
| ぬこ株式会社 | 大阪府 |
| たま株式会社 | |
| ぽぬ株式会社 | 愛知県 |
SELECT Count() FROM Account →5SELECT Count(State) FROM Account →4COUNT(field)とCOUNT_DISTINCT(field)の違い
Count(field)がその項目に値の入っているレコードの数を返すのに対して、COUNT_DISTINCT(field)はその項目のユニークな値の総数を返します。
| Name | State |
| ねこ株式会社 | 東京都 |
| いぬ株式会社 | 東京都 |
| ぬこ株式会社 | 大阪府 |
| たま株式会社 | |
| ぽぬ株式会社 | 愛知県 |
SELECT Count(State) FROM Account →4(東京都,東京都,大阪府,愛知県)SELECT Count_Distinct(State) FROM Account →3(東京都,大阪府,愛知県)AVG(field):平均
ケースの「発生源」別の「所要時間」の平均↓
SELECT Origin, AVG(DurationDemo__c) FROM Case GROUP BY Origin
COUNT():レコード数
ケースのレコード数↓
SELECT COUNT() FROM Case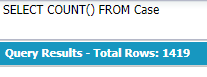
COUNT(field):当該の項目がnullではないレコードの数
親ケースを参照するケースのレコード数↓
SELECT COUNT(ParentId) FROM Case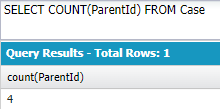
COUNT_DISTINCT(field):当該の項目のnullを除いたユニークな値の総数
ケースレコード全体で「発生源」項目に関してユニークな値の総数↓
SELECT COUNT_DISTINCT(Origin) FROM Case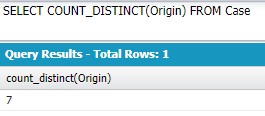
MIN(field):最小値
ケースレコード全体で最小の「所要時間」↓
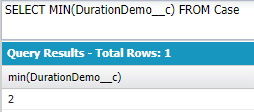
MAX(field):最大値
ケースレコード全体で最大の「所要時間」↓
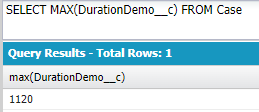
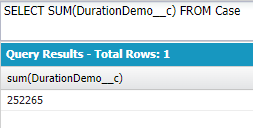
SUM(field):合計値
ケースレコード全体の「所要時間」の合計↓