
Contents
前書き
レコード数に関連する問題とそれへの対応策をある程度体系的に一覧化したい。
そもそもLDVとは何か
「LDV」とはLarge Data Volumeの各単語の頭文字を取った言葉で、日本語で表すと「大量データ」である。
Salesforceの業界では一般に「単一オブジェクトのレコード件数が200万件を超える場合」や「一度に処理するレコード件数が数万件以上である場合」にLDVを考慮する必要があるとされる。
LDVの分類
LDVは大きく次のように分類可能である。
- 単一オブジェクトのレコード件数が多い場合
- 一度に大量のレコードを処理する場合
- データ移行
- バッチ処理
以下、それぞれの対策を見ていく。
対策 – 単一オブジェクトのレコード件数が多い場合
単一オブジェクトのLDV対策は、短期的施作としての「クエリパフォーマンス向上」と長期的施作としての「そもそも大量データをSFで持たないようにする」という大きく二つの方向性に分かれる。
すなわち、以下の通りである。
- 対処療法(短期的対策)
- カスタムインデックスの利用
- SOQLが常に選択的(selective)になるよう注意する
- スキニーテーブル
- ディビジョン
- 根本療法(長期的対策)
- 定期削除
- 定期アーカイブ
- Big Object
- 外部データストレージサービス(S3など)
- 外部DB
- 外部DWH
- AppExchange
- Data Virtualization(=そもそもSFにデータを持たない)
- Salesforce Connect
- Request and Reply
- UIマッシュアップ
- Canvasでの外部サイトの埋め込み
- APIの都度コール
- 画面フロー
- LWC/VF
- 定期アーカイブ & アーカイブデータのVirtualization
対処療法① – カスタムインデックス
インデックスが自動で付与されない項目に関して、①外部ID化 ②公式サポートへのケース起票 の二つの方法によりカスタムインデックスを付与することが可能である。
◼️標準インデックス(=自動で付与されるインデックス)
- Id
- Name
- Email (※取引先責任者とリードのみ)
- Foreign Key Relationships(参照関係と主従関係)
- RecordTypeId
- Division
- CreatedDate
- SystemModStamp (LastModifiedDate)
◼️カスタムインデックス(=設定orケース申請が必要なインデックス)
- 外部ID化した項目(外部IDは以下の項目にのみ設定可能)
- 自動採番
- メール
- 数値
- テキスト
- インデックス付与のケース申請を行った項目
◼️注意事項
- 本番環境に適用されたカスタムインデックスは、その本番環境をベースに作成されたSandboxにも適用される
- 以下の項目は(ケース申請を行ったとしても)インデックスを付与できない
- 複数選択リスト
- ロングテキストエリア
- リッチテキストエリア
- 非決定性数式項目
- 暗号化されたテキスト
- 一意として指定したカスタム項目にもインデックスが自動付与されるとするドキュメントもあるが、公式ドキュメントによって内容が錯綜している。
対処療法② – selectiveなSOQLクエリ
◼️SelectiveなSOQLクエリとは何か?
一口にSOQLといっても、データテーブル全体に(JOIN付きの)フルスキャンをかけるようなパフォーマンスの低いクエリ(の元となるSOQL)もあれば、インデックス項目を用いてレコードを効率的に絞り込むパフォーマンスの高いクエリ(の元となるSOQL)もある。
Salesforceでは、以下の二つの条件を満たすSOQLは「選択的(selective)」なクエリと呼ばれ、20万件以上のレコードを含むオブジェクトに対するクエリは必ず「選択的(selective)」でなければならないとされる(※非選択的なクエリを発行した場合、ガバナ制限を監視するRuntime Engineから「System.QueryException: Non-selective query against large object type (more than 200000 rows)」エラーが返される)
- WHERE句で用いられている項目のうち一つ以上がインデックス項目である
- 当該のインデックス項目を用いたフィルタにより、レコードが特定の閾値を下回る数まで絞り込まれる
A query is selective when one of the query filters is on an indexed field and the query filter reduces the resulting number of rows below a system-defined threshold.
https://help.salesforce.com/s/articleView?id=000385213&type=1
◼️SelectiveなSOQLクエリになっているかの判定
WHERE句のフィルタ条件のうち少なくとも一つが以下を満たせばOK
- WHERE句に用いられている項目がインデックス項目である
- そのインデックス項目が以下のような形で用いられていない
- 項目の値が特定の閾値を超える
- 演算子が否定演算子(NOT EQUAL TO, NOT CONTAINS, NOT STARTS WITHなど)
- 検索条件にCONTAINSが用いられ、なおかつスキャン行数が333,333を超える
- 空の値と比較している( != ‘ ‘)
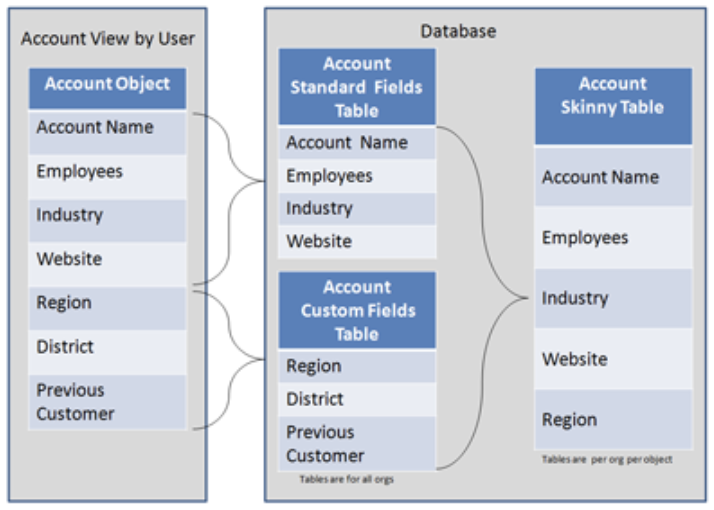
対処療法③ – スキニーテーブル
Salesforceのデータは標準項目とカスタム項目が内部的にそれぞれ異なるデータテーブルに保存されている手前、データ取得のクエリには常にJOINのオーバーヘッドが発生している。
スキニーテーブルとはこのJOINのオーバーヘッドを回避する手段の一つであり、「特定オブジェクトの指定した項目」に限定されたデータテーブルを利用することで(リストビュー・レポート・SOQLなどの)クエリパフォーマンスを向上させることが可能となる。
スキニーテーブルはSalesforceサポートにケースを起票することで作成でき、作成されるとオリジナルのデータテーブルから最新のデータが常にスキニーテーブルに関して同期されるようになる。
◼️スキニーテーブルの考慮事項
- 指定可能な項目は100項目まで
- 別オブジェクトの項目を含めることはできない
- FullSandbox以外のSandboxには自動でコピーされない
- 項目を追加したい場合、再度サポートへの連絡が必要
- トランザクション数が多いオブジェクトで利用すると、逆にパフォーマンスが低下する
◼️補足:パフォーマンス低下リスク
ヘルプの中でも強調されているが、スキニーテーブルを作成すると、DBへの変更が発生するたびにスキニーテーブルに対してデータを同期する処理が発生するようになるため、トランザクション数が多いオブジェクトに対してスキニーテーブルを有効化するとパフォーマンスが低下する。
つまり、基本的にスキニーテーブルの有効化は(大半のケースで)アンチパターンである。
海外では割と常識なのだが、日本国内ではスキニーテーブルのこのリスクが殆ど認知されていないため、ここに強調しておく。

対処療法④ – ディビジョン
ディビジョンとは、Salesforceが提供するDBのパーティション機能である。
ディビジョンを有効化すると、リード・取引先・カスタムオブジェクトとユーザはそれぞれ事前に定義したディビジョン(例:APAC・EMEA・AMER)に割り当てられる。
それにより、APACに所属するユーザがリードを検索するとAPACのリードだけが検索対象になるといった形で、(検索・レポート・リストビューなどにおける)クエリのスキャン対象レコードを限定し、パフォーマンスを向上させることが可能となる。
※別のディビジョンのデータが一切見えなくなるわけではなく、検索範囲はユーザ側で(自身へのディビジョンの割り当てに基づいて)指定可能
◼️ディビジョン利用時の考慮事項(というかデメリット)
- 管理が大変:このレコードはこのディジョンで、このユーザはこのディビジョン、といったことを管理・開発・検索時全てにおいて毎回細かく考慮する必要が出てくるため、開発コスト・管理コストが増大する。
- 変更が不可逆: ディビジョンを一度有効化すると、二度と元に戻せない
対策 – 大量データのデータ移行
大量データの移行に関するベストプラクティスはこちらの開発者ドキュメントに体系的にまとめられている。
ただし、当該のドキュメントは可能なソリューションを乱雑に規則性なく並べたものとなっており、大変分かりづらい。
以下は、当該ドキュメントで紹介されているソリューションを適切に分類・パラフレーズしたものである。
- 送信側の最適化
- 送信方法の最適化
- BulkAPIの利用:パフォーマンス向上
- UpsertをInsertとUpdateに分割:操作の高速化
- GZIP圧縮とHTTP キープアライブの利用・認証頻度を(レコード単位から)読み込み単位へ:中断回数の削減
- SOAPの場合、バッチサイズを200に近づける:バッチサイズの効率化
- 送信内容の最適化
- 送信内容を変更された項目に限定:転送データ量の削減
- 子レコードの更新時、親別にグループ化しておく:親レコードのロック競合を最小限に抑える
- 参照関係/主従関係だけ後からロードする:共有計算の延期
- 送信方法の最適化
- 受信側の最適化
- 計算の延期
- 入力規則とトリガの無効化(必要であれば後から実行):読み込みスループットの時間短縮
- 共有計算の延期
- OWDを一時的に公開/参照・更新可能に変更:Share Object Tables/Group Maintenance Tablesの計算回避
- 共有適用を延期:共有計算の延期
- 計算の延期
対策 – 大量データのバッチ処理
バッチ処理は今日スケジュールフローなどでも組むことができるが、データ量が多い場合は以下を検討する。
- Apex Batchクラス(=Database.Batchableの利用)
- SF外でのバッチ処理
Database.Batchableを用いると、一度のクエリで最大5,000万件のレコードを処理することが可能となる。
補足:通常のApexの場合、同一トランザクション内でSOQLにより取得可能なレコード件数は50,000までというガバナ制限が存在する(超えると、「Too many query rows: 50001」エラーがApex Runtimeから返される)
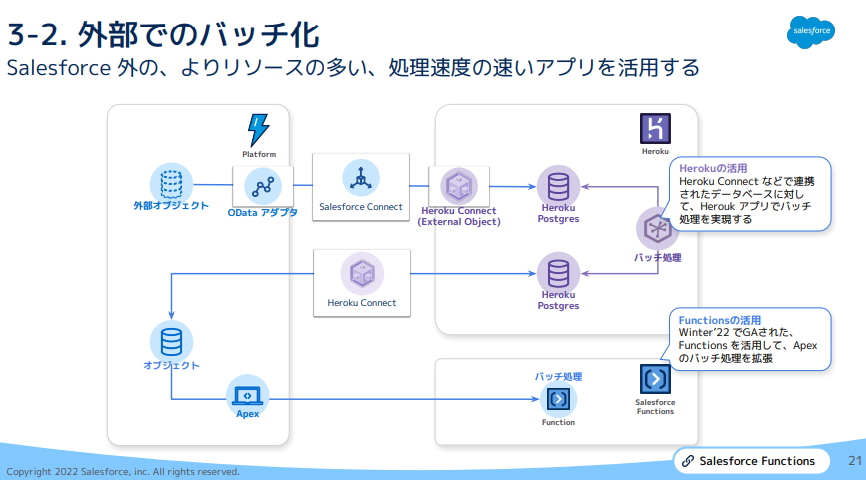
SF外でのバッチ処理については、以下の俯瞰図が分かりやすい(※AWSのLamdaに類似したSalesforce FunctionsというSFエコシステム内のサーバレスコンピューニングを用いるとAPI Call数制限への抵触を心配する必要がなくなる)
参考
Salesforce Developers – Best Practices for Deployments with Large Data Volumes