
Contents
二種類のレコードID
以下のように、Salesforceには同一レコードに対するUUIDが2種類存在する。
15桁のrecord id:702k6t3N00008h9m6
18桁のrecord id:702k6t3N00008h9m6u7K
両者の違い
①case-safeかどうか
15桁のrecord id:not case-safe = case-sensitive(大文字と小文字の区別あり)なシステムで一意性が担保されない
18桁のrecord id:case-safe = case-insensitive(大文字と小文字の区別なし)なシステムで一意性が担保される
②桁数
15桁のrecord id:15桁のbase62(=base64から記号を取り除いたもの)文字列
18桁のrecord id:15桁のrecord id + 3桁のchecksum
よくある誤解
15桁のレコードIDはCase-Sensitive(大文字と小文字の区別がある)のに対して、18桁のレコードIDはCase-Insensitive(大文字と小文字の区別がない)
昔のSalesforce Helpに記載されていた内容
→間違い
実際に、SalesforceのUI上で18桁のレコードIDの大文字と小文字を変換するとエラーが発生することが分かる。
0015g00000wd1EmAAA:正常動作
0015g00000wd1emAAA:エラー
現在のヘルプでは、過去のヘルプに記載されていた内容(すなわち、レコードIDがcase-sensitiveということ)が明示的に否定されている(※以下を参照)
18-character IDs are case-safe, but not case-insensitive. In other words, if you manually change the case of an 18-character ID, Salesforce detects that the three extra characters don’t match the case of the preceding characters and returns an error.
https://developer.salesforce.com/docs/atlas.en-us.object_reference.meta/object_reference/field_types.htm
15桁と18桁の違いはCase-Sensitiveかどうか(=大文字と小文字の区別があるかどうか)ではなく、Case-Safeかどうか(=Case-Insensitiveなシステムで一意性が担保されるかどうか)という点にある
■補足
そもそも論としてcase-sensitiveであったりなかったりする(=大文字と小文字の区別をしたりしなかったりする)のは文字列そのものではなくシステム側なので、「case-sensitiveなID」などのように文字列に対してcase-sensitiveという形容詞を適用すること自体が語用として根本的に間違いという指摘も可能である。実際に”case-sensitive id”などでググると出てくるのは旧ヘルプ記事の誤用に引っ張られたSalesforce関係の記事ばかりである。
レコードIDの仕様の深掘り
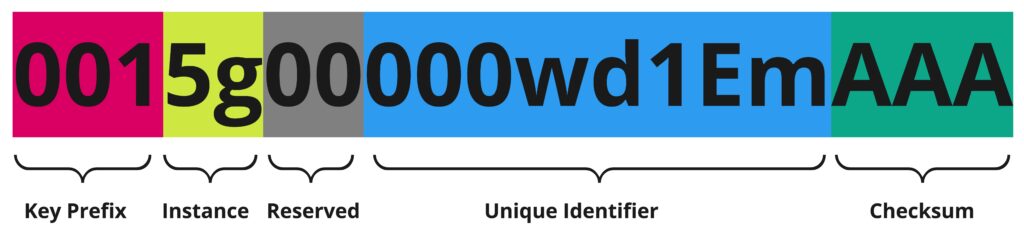
レコードIDは以下の構成要素で成立している。
1-3文字目:Key Prefix(=オブジェクトのunique identifier)
4-5文字目:Instance(=インスタンスのunique identifier)
6-7文字目:Reserved(=将来的のために確保)
8-15文字目:Unique Identifier(=レコードのunique identifier)
16-18文字目:Checksum(=前15桁のどれが大文字かの情報)
以下、それぞれ見ていく。
Key Prefix(1-3文字目)
当該のレコードのObjectを一意に表す。
例えば、取引先レコードのレコードIDは組織に関わらず必ず001から始まる仕様となっている。
この仕様を応用して、いわゆるpolymorphic relationship field(※Task/EventのWhatIdやWhoIdのように色々なオブジェクトが参照先になれる項目)の参照先オブジェクトの判定をprefixを用いて行うといった実装がしばしばなされる。
オブジェクトPrefixに関する詳細は以下記事を参照されたい。
Instance(4-5文字目)
当該レコードの利用されている組織のインスタンスを一意に表す。
ちなみに、昔はレコードIDのうち4桁目のみがインスタンス用に利用され、5-7桁目がreserveされている状態だった。しかし1桁では62インスタンスまでしか表現できないため、インスタンス数の増加に伴いレコードIDの5桁目がインスタンス用に解放されたという歴史が存在する(らしい。真偽不明。ソースはこちら。)
Reserved(6-7文字目)
将来のためにreserveされている。
ちなみに、レコードIDの構造について解説している海外サイトを見ると、6桁目のみがreserveされ、7-15桁目までがrecordのunique identifierとして利用されているとしている情報も多いが、本記事では以下をSoT(Source of Truth)とする。

Unique Identifier(8-15文字目)
レコードを一意に表す。
Checksum(16-18桁目)
前15桁のうち、どれが大文字(でどれが小文字)かの情報を有する。
このchecksumにより、case-insensitiveなシステムでもrecord idの一意性が担保される(Salesforce風に表現すれば、case-safeな状態が実現される)
ちなみにchecksumの算出ロジックは以下のように極めてシンプルなものである。ロジックを誤解を恐れずに簡略化してしまえば、大文字小文字大文字という文字の並びを101のように変換した上で、101のパターンならば’E’ といった仕方で表現する仕組みとなっている(詳しくはこちらを参照)
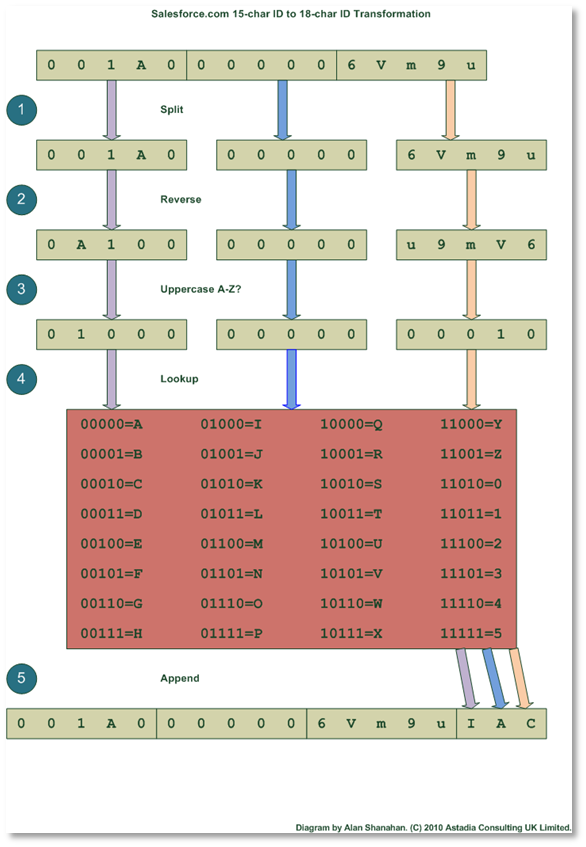
二種類のレコードIDの変換方法
■18桁→15桁
末尾の3桁(checksum)を無くすだけでOK
0015g00000wd1EmAAA
■15桁→18桁
checksumを計算して、末尾に追加する必要あり。
ロジック自体はシンプルなので如何様にでもなるが、ポピュラーな変換方法としては以下が挙げられる。
- 数式のCASESAFEIDメソッド
- オンラインで公開されている変換ツールを利用する
- 自力でコード書く(SF公式がサンプルで公開しているJSコードはこちら)
そもそもなぜこのように二種類のレコードIDが存在するのか?
- 元々Salesforceは15桁のレコードIDを利用していた。
- Salesforceが内部的に利用しているDB(昔はOracleで今はPostgreSQL)はcase-sensitiveだったのでそれで問題なかった。
- ところが世の中にはcase-insensitiveなシステムやツール(代表例:Access, Excel)が存在し、15桁のIDではUUIDとなり得ないことが判明した(※システム連携などで困る事例が多発した)
- そこで15桁のレコードIDとは別に、18桁のレコードIDを作成した。
現在、内部的なDBのunique keyとしては15桁のレコードIDが引き続き利用されている一方で、エンドユーザである我々に対しては大半のUIやAPIにおいて18桁のレコードIDが返される仕様になっている。
(オブジェクト名が分からない)レコードIDからレコード詳細ページに直アクセスする小技
0015g00000Wd1emAAB
↓
■通常のURL
https://regardie.lightning.force.com/lightning/r/Account/0015g00000Wd1emAAB/view
■Lightning
https://regardie.lightning.force.com/0015g00000Wd1emAAB
■Classic
https://regardie.my.salesforce.com/0015g00000Wd1emAAB
https://regardie.my.salesforce.com/0015g00000Wd1em
参考
Salesforce Help – Locate the Unique ID of a Record in Salesforce
An Insider View of the Salesforce Architecture